







The Teacher-Architect: Using Historical Logs to Preserve
Use historical logs to make AI-supported learning visible: prompts, revisions, source checks and learner decisions that teachers can question as formative evidence.


Use historical logs to make AI-supported learning visible: prompts, revisions, source checks and learner decisions that teachers can question as formative evidence.
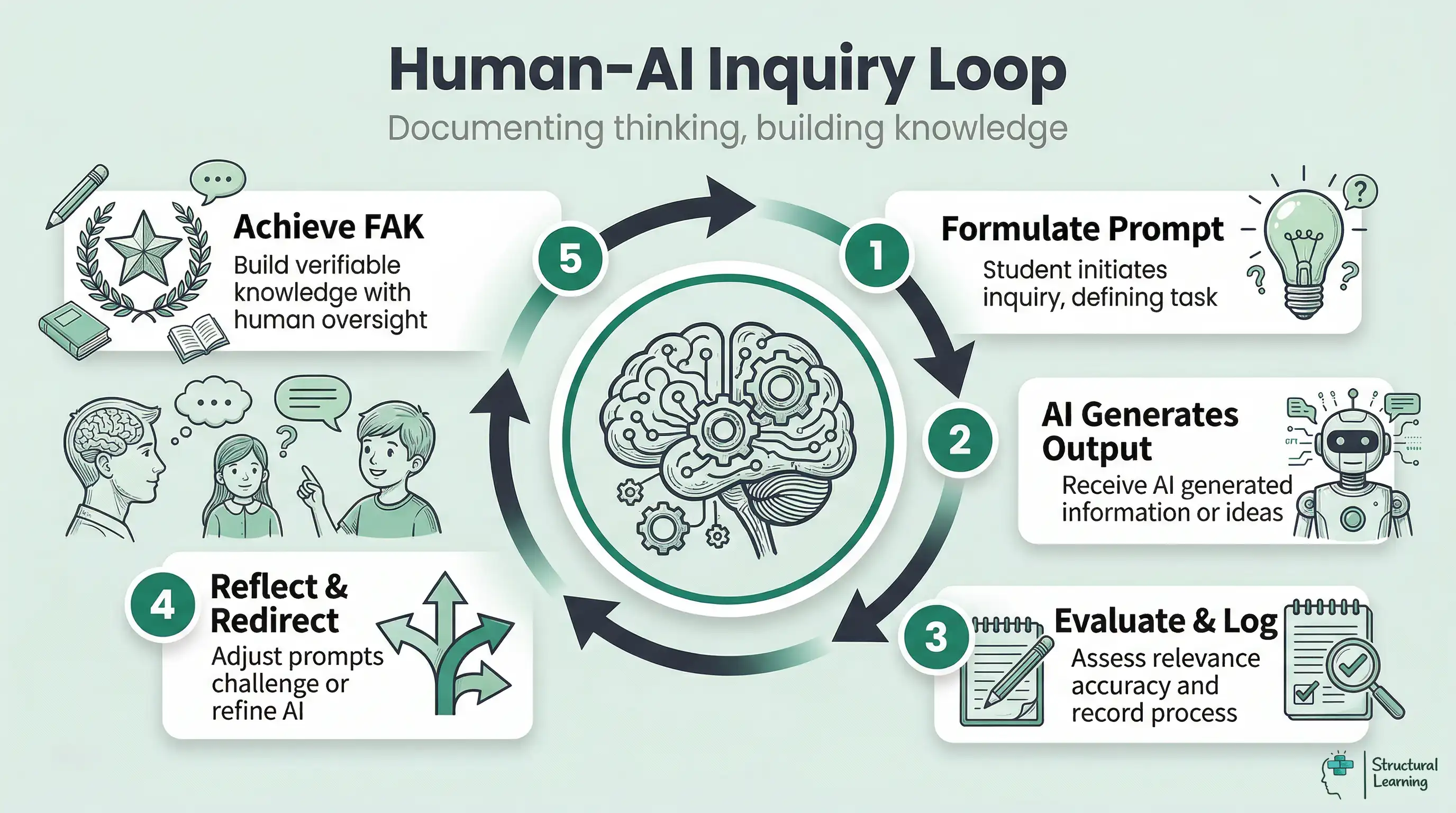
The Teacher-Architect: Using Historical Logs to Preserve describes a classroom approach. Teachers design AI tasks so learners show clear evidence of their thinking. In AI education, a historical log is a time-ordered record of a learner's prompts, AI responses, source checks, revisions and reasons for accepting or rejecting suggestions. Teachers use the log as formative evidence, not proof of authorship, so they can question the learning process when AI outputs are fluent but opaque (Bearman & Ajjawi, 2023).
For example, in a Year 9 history lesson on the causes of the First World War, a learner records the first AI summary, flags an unsupported claim, checks it against two sources and rewrites the prompt. The teacher can then ask why that claim was rejected, where the evidence improved and what the learner would do differently next time.
AI worries echo earlier debates about calculators. Educators feared that easy access to machines would weaken mathematical fluency, or learners' quick and accurate use of basic maths. Yet the research record is mixed: Hembree and Dessart's meta-analysis found that calculator use alongside normal instruction generally did not damage paper-and-pencil skills. It could also improve problem solving and attitudes to mathematics.
The classroom lesson is not that tools automatically improve learning. It is that teachers have to redesign the task. Historical work on educational technology shows that new machines change learning only when curriculum, assessment and classroom routines change with them.
The same principle could apply to generative AI. A documented historical log can make prompt choices, revisions, source checks and rejected AI suggestions visible, so the assessment conversation moves from "did the machine write this?" to "what evidence of thinking can the learner show?"
A safer way to describe the classroom model is as a documented human-AI inquiry cycle. The learner records what they asked, what the model returned, what they doubted, what they checked and how their next question changed.
This process-focused approach values learning, not just the final piece of writing. Black (1998) argued that assessment supports learning when teachers use evidence to adapt their teaching. The same formative principle applies here. The teacher can see partial understanding, ask follow-up questions and give feedback while the learner's thinking is still developing.
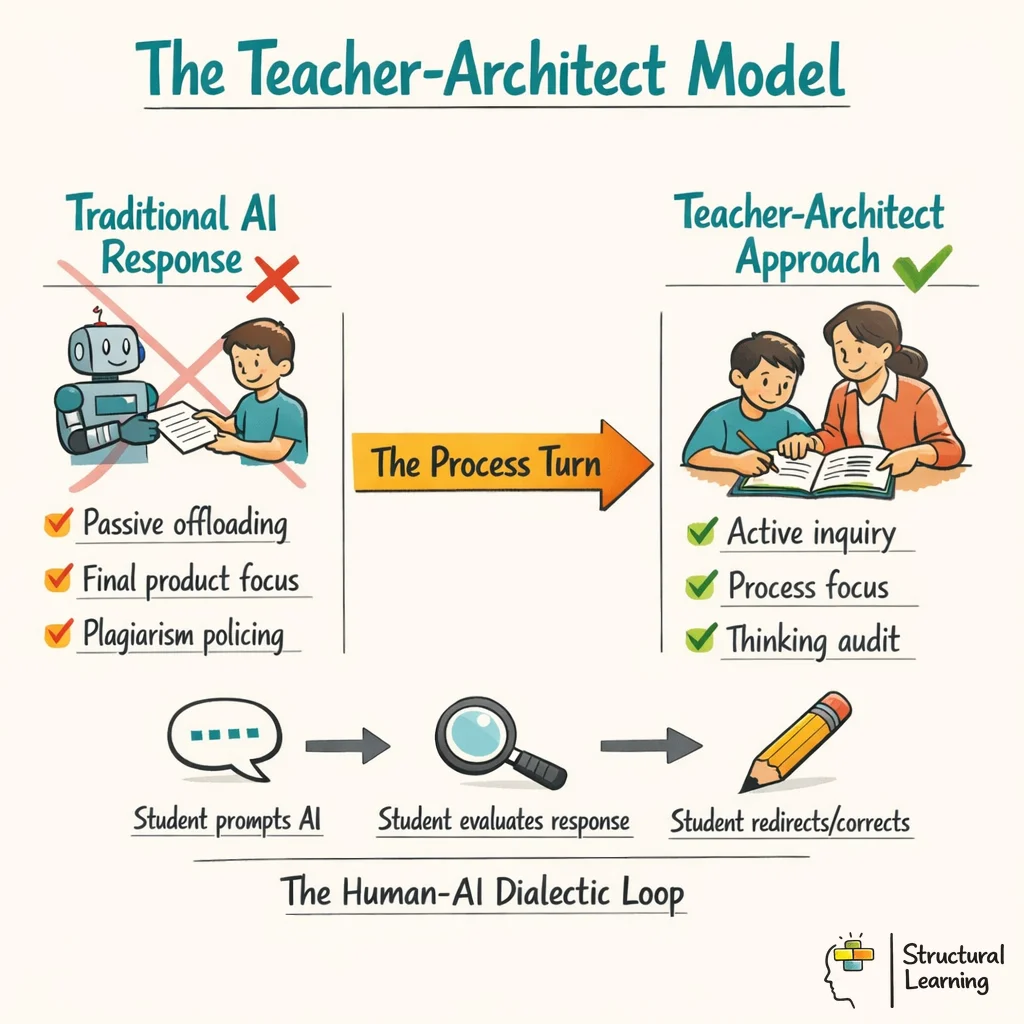
For teachers, the design question is clear: how can the task stop learners from offloading their thinking to AI and require them to use AI as a tool for checking, explaining and improving their reasoning?
It is best to treat documentation as indirect support for self-regulated learning. It gives learners a record they can use to plan, monitor their work and evaluate after the task. This fits with metacognition research. It does not prove that any single AI log format improves outcomes.
Cognitive offloading research explains both the opportunity and the risk. External tools can reduce the processing load of a task, but learners still need to monitor whether the tool is helping or replacing their thinking (Risko & Gilbert, 2016; Flavell, 1979). A log is useful only when it prompts that monitoring.
Without that record, AI use can become invisible. The teacher sees an answer, but not the rejected ideas, source checks or moments where the learner changed direction. The value of the historical log is therefore evidential and pedagogical: it creates something concrete to question.
Ataş and Yildirim's design-based research on shared metacognition is useful, but it is narrower than a direct study of AI history logs. Shared metacognition means learners thinking together about how they are learning. The study supports orientation-planning, monitoring and evaluation-reflection in online group learning. These ideas can guide the design of AI tasks.
This matters especially in the context of generative AI. Bjork (1994) argued that learners can misjudge what they know when fluent processing feels like mastery. The machine's "fluency" can create the same "fluency illusion", where the learner believes they understand a topic simply because the AI has summarised it clearly and confidently (Bjork et al., 2013). The Audit Trail disrupts this illusion by requiring learners to "show the work" of their logic, much like traditional formative assessment practices.
In practice, the learner should remain in the loop: checking claims, asking for alternatives, rejecting weak answers and documenting why the final judgement is theirs. That is a classroom routine, not a guarantee built into the technology.
When teachers use the Historical Log, attention shifts from the final product to the documented development of thought. This helps the Teacher-Architect see the scaffolding of the learner's thinking.
Assessment that asks for the process can also make feedback more useful. Instead of marking only a polished final answer, the teacher can respond to the point where the learner misunderstood a concept, accepted a weak source or failed to challenge an AI suggestion.
Decision records are not forensic proof on their own, but they do raise the quality of the evidence conversation. A learner who can explain why a prompt changed, why a source was rejected and why a claim survived checking is showing more than output completion.
One concern for teachers is that learners can ask AI to simulate a historical log after they have finished a paper. There is no technical guarantee that a log is authentic, so schools should avoid treating it as automatic proof.
AI-generated logs can look plausible. AI-text detectors are not reliable enough to settle authorship questions on their own. Detection studies show that generated text can be hard to identify, especially after paraphrasing. They also show that human writing can be misclassified.
The practical safeguard is not a branded construct. It is a pattern of evidence: timestamps where available, drafts that match the lesson sequence, source notes, teacher questioning and visible changes of direction that the learner can explain.
Look for visible challenge rather than smooth compliance. A stronger log shows the learner questioning an answer, asking for evidence, checking a source and changing course when the evidence does not support the claim. That is useful classroom evidence, but it is not a validated marker of human agency.
Teachers can use timing and task sequence as context, but they should still ask the learner to explain the choices. A timestamp may support a conversation; it should not replace professional judgement.
Sadasivan and colleagues argue that reliable AI-text detection is difficult in real classrooms and other practical settings. Liang and colleagues found that GPT detectors can wrongly label non-native English writing as AI-generated. For this reason, historical logs should be part of a wider assessment conversation. They should not become a detector-led compliance routine.
Historical logs may reduce some uncertainty about AI use, but they also add a new routine for teachers to manage. The workload argument is credible only when the log is short, structured and directly connected to feedback.
The strongest case is formative, not administrative. A log can help the teacher identify where feedback is needed: the first weak prompt, the unsupported claim, the copied explanation or the missed opportunity to compare sources.
AI detectors are unreliable enough that schools should be cautious about using them as sole evidence (Weber-Wulff et al., 2023; Liang et al., 2023). A documented log gives teachers a richer basis for questioning, but it does not remove the need for judgement.
When the log is structured by stages, feedback can be more precise. Teachers can ask about the moment a learner accepted a hallucinated source, ignored a contradiction or changed the question after new evidence appeared.
Teachers do not rely only on plagiarism checks after the work is done. They design inquiry-based learning pathways instead. They also look beyond the final product. They review learners' thinking processes and use them to give feedback.
Generative AI does mean schools need to rethink what counts as achievement. Producing text is no longer enough; learners need to show how they selected, questioned, verified and improved the information they used.
Bearman and Ajjawi (2023) argue that education needs pedagogy for working with AI systems whose outputs are not transparent. In other words, teachers need ways to teach when they cannot fully see how an AI answer was made. The World Economic Forum's Future of Jobs Report 2023 also lists analytical thinking, creative thinking, AI and big data as prominent workforce skills.
When information is easy to generate, learners need to direct, organise and check it well. Academic rigour means careful, disciplined thinking. It is shown through selecting evidence, checking sources and revising work responsibly. A polished paragraph alone is not enough.
For classroom purposes, the useful test is simple: can the learner explain how today's AI-supported work will help them make a better decision, solve a similar problem or ask a stronger question next time?
This research has practical implications for how you teach with AI. Consider implementing these approaches: Use this as a starting point for professional discussion. Identify the learner's current need, and record evidence from several lessons. Then, agree on the next classroom adjustment with the SENCO or family.
For the wider picture, explore our AI and EdTech tools hub, our home for evidence-based AI guidance across policy, lesson planning, and classroom practice.
Historical logs document the process behind AI-supported work. They record prompts, responses, corrections, rejected sources and changes of direction instead of showing only the final answer.
Teachers shift their focus from being plagiarism detectors to designers of inquiry loops. They assess the structural integrity of a student's thinking by reviewing their documented dialogue with the machine. In practice, this means setting assignments where the process of refining prompts and challenging AI outputs is graded rather than just the final submitted text.
Requiring learners to document their inquiry process can disrupt the fluency illusion, where a clear explanation feels like understanding before the learner has tested it. The benefit depends on teacher questioning and source checking, not on the log existing by itself.
Cognitive offloading research suggests that people often use tools to reduce mental demand. That can be helpful, but in AI tasks teachers need learners to monitor the tool, explain the judgement and retain responsibility for the final claim.
Common mistakes include marking only the final output and allowing private, unlogged AI use for high-stakes tasks. Teachers should also avoid treating detector scores as proof. Learners need to be taught how to verify claims and cite sources.
Learners gain agency when AI use is visible enough to question. A historical log does not prove authorship, but it can make the learning process clearer by showing prompts, revisions, checks and changes of direction.
Teachers gain more useful evidence when the task asks learners to justify logic, compare sources and explain why they trusted or rejected an AI suggestion.
Used carefully, historical logs move the classroom conversation away from detector scores. They bring attention back to assessment design. They help teachers ask clearer questions about process, evidence and accountability.
Akgun, M., & Toker, S. (2024). Evaluating the effect of pretesting with conversational AI on retention of needed information. arXiv. View arXiv record.
Ataş, A. H., & Yildirim, Z. (2024). A shared metacognition-focused instructional design model for online collaborative learning environments. Educational Technology Research and Development. View DOI record.
Bearman, M., & Ajjawi, R. (2023). Learning to work with the black box: Pedagogy for a world with artificial intelligence. British Journal of Educational Technology, 54(5), 1160-1173. View Deakin record.
Bjork, R. A., Dunlosky, J., & Kornell, N. (2013). Self-regulated learning: Beliefs, techniques, and illusions. Annual Review of Psychology, 64, 417-444. View UCLA-hosted PDF.
Black, P., & Wiliam, D. (1998). Assessment and classroom learning. Assessment in Education: Principles, Policy and Practice, 5(1), 7-74. View university-hosted PDF.
Department for Education. Generative artificial intelligence (AI) in education. View GOV.UK guidance.
Flavell, J. H. (1979). Metacognition and cognitive monitoring: A new area of cognitive-developmental inquiry. American Psychologist, 34(10), 906-911. View DOI record.
Hembree, R., & Dessart, D. J. (1986). Effects of hand-held calculators in precollege mathematics education: A meta-analysis. Journal for Research in Mathematics Education, 17(2), 83-99. View ERIC record.
Liang, W., Yuksekgonul, M., Mao, Y., Wu, E., & Zou, J. (2023). GPT detectors are biased against non-native English writers. Patterns, 4(7), 100779. View Stanford SCALE record.
Risko, E. F., & Gilbert, S. J. (2016). Cognitive offloading. Trends in Cognitive Sciences, 20(9), 676-688. View PubMed record.
Sadasivan, V. S., Kumar, A., Balasubramanian, S., Wang, W., & Feizi, S. (2023). Can AI-generated text be reliably detected? arXiv. View arXiv record.
Weber-Wulff, D., Anohina-Naumeca, A., Bjelobaba, S., Foltýnek, T., Guerrero-Dib, J., Popoola, O., Šigut, P., & Waddington, L. (2023). Testing of detection tools for AI-generated text. International Journal for Educational Integrity, 19, 26. View open-access article.
World Economic Forum. (2023). The future of jobs report 2023. View report page.
Historical logs should not be treated as settled evidence of learning. First, the evidence base is indirect. The approach draws on formative assessment, metacognition and cognitive offloading, but there are still few classroom trials showing that AI historical logs improve attainment across subjects. Bennett (2011) warned that formative assessment claims can become too broad when definitions and subject demands are unclear, so schools need specific success criteria for what a good log shows.
Second, logs can record performance rather than understanding. Bjork (1994) showed that learners often misread fluency as mastery, and Bjork, Dunlosky and Kornell (2013) linked this to poor self-regulated learning choices. A neat AI conversation can therefore hide weak retrieval, shallow source checking or untested knowledge. Teachers should probe the log orally or through short follow-up tasks.
Third, authenticity, workload and fairness remain unresolved. Sadasivan et al. (2023) and Weber-Wulff et al. (2023) show that AI-generated text is difficult to detect reliably, while Liang et al. (2023) found detector bias against non-native English writers. Selwyn (2019) also warns against treating AI education as a technical problem alone; logging can become surveillance or extra administration if schools collect records without a clear assessment purpose. Cultural norms around challenge, citation and teacher authority will affect how learners document disagreement. Despite these limits, the historical log remains valuable because it moves AI assessment towards visible evidence, teacher questioning and accountable judgement rather than simple output policing.
These sources replace the future-dated, placeholder and unrelated items previously shown here. They support the article's cautious position on AI use, documentation, metacognition and detector limits.
Learning to work with the black box View Deakin record
Bearman and Ajjawi (2023), British Journal of Educational Technology.
This is the strongest source for the article's central point: teachers need pedagogy for working with AI outputs that are not fully transparent.
Generative artificial intelligence in education View GOV.UK guidance
Department for Education.
Use this for current UK school-facing principles: human checking, privacy, safety, transparency and professional responsibility around generative AI.
Testing of detection tools for AI-generated text View open-access article
Weber-Wulff et al. (2023), International Journal for Educational Integrity.
This supports the warning that AI detectors are not reliable enough to use as sole evidence in academic-integrity decisions.
GPT detectors are biased against non-native English writers View Stanford SCALE record
Liang et al. (2023), Patterns.
This is a key fairness source for schools because detector-led workflows can misclassify non-native English writing.
Cognitive offloading View PubMed record
Risko and Gilbert (2016), Trends in Cognitive Sciences.
This source anchors the article's distinction between helpful tool use and passive outsourcing of thinking.
Self-regulated learning: Beliefs, techniques and illusions View UCLA-hosted PDF
Bjork, Dunlosky and Kornell (2013), Annual Review of Psychology.
This supports the article's caution about fluency illusions: clear explanations can feel like learning before understanding has been tested.
A shared metacognition-focused instructional design model View DOI record
Ataş and Yildirim (2024), Educational Technology Research and Development.
This source is relevant to the design of collaborative online tasks, but it should not be overclaimed as direct proof for AI historical logs.
Evaluating the effect of pretesting with conversational AI View arXiv record
Akgun and Toker (2024), arXiv preprint.
This is an emerging AI-learning source, useful as a preprint only. It should not be used as evidence for calculator history or broad claims that AI improves learning.



